What is HBase?
Hbase is Column-Oriented , Open-Source, Multidimensional, Distributed database. It run on the top of HDFS
Why we use Habse?
Hbase provide random read and write, Need to do thousand of operation per second on large data set.
List the main component of HBase?
Zookeeper
Catalog Tables
Master
RegionServer
Region
How many Operational command in Hbase?
There are five main command in HBase.
1. Get
2. Put
3. Delete
4. Scan
5. Increment
What happens if we change the block size of a column family on an already populated database?
When we change the block size of the column family, the new data takes the new block size while the old data is within the old block size. When the compaction occurs, old data will take the new block size. "New files, as they are flushed, will have the new block size, whereas existing data will continue to be read correctly. After the next major compaction, all data should be converted to the new block size."
When should you use Hbase?
- Data size is huge: When you have few millions or thousands of record, traditional RDBMS wins hands down. For Hbase to be really good on RoI, your application should have millions/billions of rows. In Hbase, you would be dealing with billions of rows for update/delete/insert.
- Complete Redesign: When you are migrating from RDBMS to Hbase, you consider it as a complete redesign rather than just changing the ports. You cannot use your application by minor changes. It is a complete redesign of the application with signification investment of time and money.
- SQL-Less commands: In RDBMS you have several features like secondary indexes, inner joins, transactions, typed columns etc. Make sure that you can live without those frills.
- Infrastructure investment: For Hbase to be really useful, you need to have a big enough cluster (min 5). This would allow to use the feature of Hbase (distributed storage etc.. ). Otherwise, you are better off with RDBMS database schema.
What
is the difference between Hbase and HDFS?
HDFS is a good storage for large files. Of course, it is not built only for storage but for distributed computing. HDFS is not a good source for retrieval/update of files/data. Hbase is a good tool for fast retrieval/update of the data as itintrnally indexes all the files.
HDFS is a good storage for large files. Of course, it is not built only for storage but for distributed computing. HDFS is not a good source for retrieval/update of files/data. Hbase is a good tool for fast retrieval/update of the data as itintrnally indexes all the files.
|
HBASE
|
HADOOP
|
|
It is distributed,
column oriented, versioned data storage system. Low latency access to small
amount of data in big data set.
|
Good for accessing
data from large files (>64 MB)
|
|
Flexible data model.
Fast search across tables.
|
It is good for write
once and read many times. It is not good for random read and writes.
|
|
Scales well in terms
of write as well as volume of data.
|
It is the base for
HBASE.
|
|
HBASE helps Hadoop
overcome the challenges in random read and write.
|
What
is the difference between HBASE and RDBMS?
Tabulating the difference in the following table:
Tabulating the difference in the following table:
|
HBASE
|
RDBMS
|
|
It is distributed,
column oriented, versioned data storage system.
|
It is designed to
follow FIXED schema. It is row-oriented databases and doesn’t natively scale
to distributed storage.
|
|
HDFS is underlying
layer of HBase and provides fault tolerance and linear scalability. It
doesn’t support secondary indexes and support data in key-value pair.
|
It supports
secondary indexes and improvises data retrieval through SQL language.
|
|
It supports dynamic
addition of column in table schema. It is not relational database like RDBMS.
|
It has slow learning
curve and support complex joins and aggregate functions.
|
|
HBASE helps Hadoop
overcome the challenges in random read and write.
|
Does Hbase suppport SQL?
No. Hbase is not suitable for SQLish type of syntax. Hive is the tool which provides SQL like syntax. The SQL support for Hbase is under development.
What are the schema design example in Hbase compared to SQL?
There is a big difference between row-oriented/RDBMS and column oriented database. For example, if I have a User and need to store the friendship, my design would look something like this in RDBMS
user = pkey: userId
Friendship = pkeySomething, userId, friendId, ....
This would mean that as the number of friendId increase, number of rows in the table would increase. this becomedifficult when there are thousands of record and there is a criss-cross of friend.
This things works very well in columner database. You can have a friend column group and keep on adding column as soon as the number of friends increase. It shows no problem in scaling up whenever required.
No. Hbase is not suitable for SQLish type of syntax. Hive is the tool which provides SQL like syntax. The SQL support for Hbase is under development.
What are the schema design example in Hbase compared to SQL?
There is a big difference between row-oriented/RDBMS and column oriented database. For example, if I have a User and need to store the friendship, my design would look something like this in RDBMS
user = pkey: userId
Friendship = pkeySomething, userId, friendId, ....
This would mean that as the number of friendId increase, number of rows in the table would increase. this becomedifficult when there are thousands of record and there is a criss-cross of friend.
This things works very well in columner database. You can have a friend column group and keep on adding column as soon as the number of friends increase. It shows no problem in scaling up whenever required.
Can you
provide an example for good denormalization in
Hbase and how it is held consistent. As I think of user table, and I
delete the user with userid=123, do I have to walk through all the user column
family friend toguaranty consistency? is denormalization in
Hbase is used to only avoid join?
In Hbase, you loose all the concept of foreign key. You just have primary key... that is it. There are no foreign key or secondary indexes in Hbase. It is the responsibility of the developer to delete/update the related rows to avoid the inconsistency in reading the data. For small application, RDBMS is the right choice and this become important when you are dealing wiht billions of rows.
Suppose, we want to find user's favorite link and also the link which is favorited by the user. In RDBMS, we will keep a favorite link in the users table and user's name in the link_favorite. These two tables will be linked. This doesn't work the same way in column value pair as these two tables would not be connected in Hbase.
In Hbase, you loose all the concept of foreign key. You just have primary key... that is it. There are no foreign key or secondary indexes in Hbase. It is the responsibility of the developer to delete/update the related rows to avoid the inconsistency in reading the data. For small application, RDBMS is the right choice and this become important when you are dealing wiht billions of rows.
Suppose, we want to find user's favorite link and also the link which is favorited by the user. In RDBMS, we will keep a favorite link in the users table and user's name in the link_favorite. These two tables will be linked. This doesn't work the same way in column value pair as these two tables would not be connected in Hbase.
Why does
Hbase depends on HDFS? For example, HDFS extracts away the exact location
file is written to however when Hbase node stores a file, it need to make
sure that an Hbase node
stores the file on the same physical node (so there is code in HDFS which takes
care of this part).
Hbase doesn't need a big part of HDFS but since it was clone of Big Table which relied on Google File System, it has the dependency.
http://www.quora.com/HBase/Why-does-HBase-depend-on-HDFS
Hbase doesn't need a big part of HDFS but since it was clone of Big Table which relied on Google File System, it has the dependency.
http://www.quora.com/HBase/Why-does-HBase-depend-on-HDFS
How you retrieve data from Hbase table?
http://cook.coredump.me/post/19672191046/hbase-client-example
HBase Shell
hbase(main):001:0>
create 'test', 'cf'
0 row(s) in 3.8890
seconds
hbase(main):002:0>
put 'test', 'row1', 'cf:a', 'value1'
0 row(s) in 0.1840
seconds
hbase(main):003:0>
scan 'test'
ROW COLUMN+CELL
row1 column=cf:a,
timestamp=1332311427315, value=value1
1 row(s) in 0.1160
seconds
hbase(main):004:0>
Hbase Interview Questions
What happens if we change
the block size of a column family on an already populated database?
When we change the block size of the column family, the new data takes the new block size while the old data is within the old block size. When the compaction occurs, old data will take the new block size. "New files, as they are flushed, will have the new block size, whereas existing data will continue to be read correctly. After the next major compaction, all data should be converted to the new block size."
When we change the block size of the column family, the new data takes the new block size while the old data is within the old block size. When the compaction occurs, old data will take the new block size. "New files, as they are flushed, will have the new block size, whereas existing data will continue to be read correctly. After the next major compaction, all data should be converted to the new block size."
When should you use Hbase?
·
Data
size is
huge: When you have few millions or thousands of record,
traditional RDBMS wins hands down. For Hbase to be really good on
RoI, your application should have millions/billions of rows. In
Hbase, you would be dealing with billions of rows for
update/delete/insert.
·
Complete Redesign: When you are migrating from RDBMS to
Hbase, you consider it as a complete redesign rather than just changing
the ports. You cannot use your application by minor changes. It is a complete
redesign of the application with signification investment of time and money.
·
SQL-Less commands: In RDBMS you have several features like
secondary indexes, inner joins, transactions, typed columns etc. Make
sure that you can live without those frills.
·
Infrastructure investment: For Hbase to be really useful,
you need to have a big enough cluster (min 5). This would allow to use the
feature of Hbase (distributed storage etc.. ). Otherwise, you are better
off with RDBMS database schema.
<a href="http://www.f2finterview.com/web/HBase/2/"><b>F2F
Interview | HBase | Interview Questions & Answers</b></a>

What is the difference between Hbase and HDFS?
HDFS is a good storage for large files. Of course, it is not built only for storage but for distributed computing. HDFS is not a good source for retrieval/update of files/data. Hbase is a good tool for fast retrieval/update of the data as itintrnally indexes all the files.
|
HBASE
|
HADOOP
|
|
It is distributed, column
oriented, versioned data storage system. Low latency access to small amount
of data in big data set.
|
Good for accessing data from
large files (>64 MB)
|
|
Flexible data model. Fast
search across tables.
|
It is good for write once and
read many times. It is not good for random read and writes.
|
|
Scales well in terms of write
as well as volume of data.
|
It is the base for HBASE.
|
|
HBASE helps Hadoop overcome
the challenges in random read and write.
|

What is the difference between HBASE and RDBMS?
Tabulating the difference in the following table:
|
HBASE
|
RDBMS
|
|
It is distributed, column
oriented, versioned data storage system.
|
It is designed to follow FIXED
schema. It is row-oriented databases and doesn’t natively scale to
distributed storage.
|
|
HDFS is underlying layer of
HBase and provides fault tolerance and linear scalability. It doesn’t support
secondary indexes and support data in key-value pair.
|
It supports secondary indexes
and improvises data retrieval through SQL language.
|
|
It supports dynamic addition
of column in table schema. It is not relational database like RDBMS.
|
It has slow learning curve and
support complex joins and aggregate functions.
|
|
HBASE helps Hadoop overcome
the challenges in random read and write.
|
Does Hbase suppport SQL?
No. Hbase is not suitable for SQLish type of syntax. Hive is the tool which provides SQL like syntax. The SQL support for Hbase is under development.
What are the schema design example in Hbase compared to SQL?
There is a big difference between row-oriented/RDBMS and column oriented database. For example, if I have a User and need to store the friendship, my design would look something like this in RDBMS
user = pkey: userId
Friendship = pkeySomething, userId, friendId, ....
This would mean that as the number of friendId increase, number of rows in the table would increase. this becomedifficult when there are thousands of record and there is a criss-cross of friend.
This things works very well in columner database. You can have a friend column group and keep on adding column as soon as the number of friends increase. It shows no problem in scaling up whenever required.
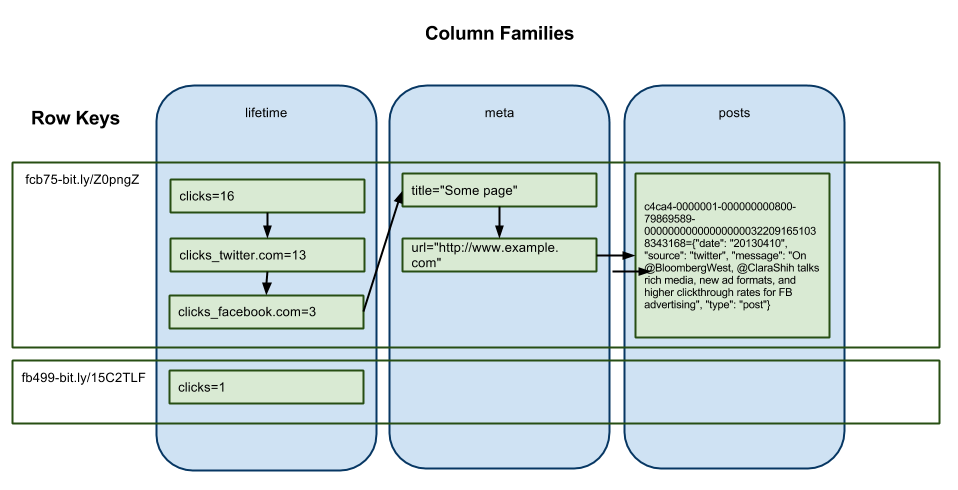
Can you provide an example for good denormalization in Hbase and how it is held consistent. As I think of user table, and I delete the user with userid=123, do I have to walk through all the user column family friend toguaranty consistency? is denormalization in Hbase is used to only avoid join?
In Hbase, you loose all the concept of foreign key. You just have primary key... that is it. There are no foreign key or secondary indexes in Hbase. It is the responsibility of the developer to delete/update the related rows to avoid the inconsistency in reading the data. For small application, RDBMS is the right choice and this become important when you are dealing wiht billions of rows.
Suppose, we want to find user's favorite link and also the link which is favorited by the user. In RDBMS, we will keep a favorite link in the users table and user's name in the link_favorite. These two tables will be linked. This doesn't work the same way in column value pair as these two tables would not be connected in Hbase.
http://www.f2finterview.com/web/HBase/2/?page=9
Why does Hbase depends on HDFS? For example, HDFS extracts away the exact location file is written to however when Hbase node stores a file, it need to make sure that an Hbase node stores the file on the same physical node (so there is code in HDFS which takes care of this part).
Hbase doesn't need a big part of HDFS but since it was clone of Big Table which relied on Google File System, it has the dependency.
http://www.quora.com/HBase/Why-does-HBase-depend-on-HDFS
How you retrieve data from Hbase table?
http://cook.coredump.me/post/19672191046/hbase-client-example
HBase Shell
hbase(main):001:0> create 'test', 'cf'0 row(s) in 3.8890 seconds hbase(main):002:0> put 'test', 'row1', 'cf:a', 'value1'0 row(s) in 0.1840 seconds hbase(main):003:0> scan 'test'ROW COLUMN+CELL row1 column=cf:a, timestamp=1332311427315, value=value1 1 row(s) in 0.1160 seconds hbase(main):004:0>
Java Source
import java.io.IOException; import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.HBaseConfiguration;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.ResultScanner;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.util.Bytes; public class HBaseClient { public static void main(String[] arg) throws IOException { Configuration config = HBaseConfiguration.create(); config.set("hbase.zookeeper.quorum", "hadoop1"); HTable testTable = new HTable(config, "test"); for (int i = 0; i < 100; i++) { byte[] family = Bytes.toBytes("cf"); byte[] qual = Bytes.toBytes("a"); Scan scan = new Scan(); scan.addColumn(family, qual); ResultScanner rs = testTable.getScanner(scan); for (Result r = rs.next(); r != null; r = rs.next()) { byte[] valueObj = r.getValue(family, qual); String value = new String(valueObj); System.out.println(value); } } testTable.close(); }}
How to open a connection in Hbase?
If you are going to open connection with the help of Java API.
The following code provide the connection
Configuration myConf = HBaseConfiguration.create();
HTableInterface usersTable = new HTable(myConf, "users");
What is MemStore in Hbase?
What is Block Cache in Hbase?
What is data versioning in HBase?
How can you define cell in Hbase?
What is major and minor compaction in HBase?
NoSQL?
HBase is a type of NoSQL database. NoSQL is a general term meaning that the database isnt an RDBMS which supports SQL as its primary access language, but there are many types of NoSQL databases: BerkeleyDB is an example of a local NoSQL database, whereas HBase is very much a distributed database. Technically speaking, HBase is really more a Data Store than Data Base because it lacks many of the features you find in an RDBMS, such as typed columns, secondary indexes, triggers, and advanced query languages, etc.
However, HBase has many features which supports both linear and modular scaling. HBase clusters expand by adding RegionServers that are hosted on commodity class servers. If a cluster expands from 10 to 20 RegionServers, for example, it doubles both in terms of storage and as well as processing capacity. RDBMS can scale well, but only up to a point - specifically, the size of a single database server - and for the best performance requires specialized hardware and storage devices. HBase features of note are
Strongly consistent reads/writes: HBase is not an eventually consistent DataStore. This makes it very suitable for tasks such as high-speed counter aggregation.Automatic sharding: HBase tables are distributed on the cluster via regions, and regions are automatically split and re-distributed as your data grows.
When Should I Use HBase?
HBase isnt suitable for every problem.
First, make sure you have enough data. If you have hundreds of millions or billions of rows, then HBase is a good candidate. If you only have a few thousand/million rows, then using a traditional RDBMS might be a better choice due to the fact that all of your data might wind up on a single node (or two) and the rest of the cluster may be sitting idle.
Second, make sure you can live without all the extra features that an RDBMS provides (e.g., typed columns, secondary indexes, transactions, advanced query languages, etc.) An application built against an RDBMS cannot be ported to HBase by simply changing a JDBC driver, for example. Consider moving from an RDBMS to HBase as a complete redesign as opposed to a port.
Third, make sure you have enough hardware. Even HDFS doesnt do well with anything less than 5 DataNodes (due to things such as HDFS block replication which has a default of 3), plus a NameNode.
What Is The Difference Between HBase and Hadoop/HDFS?
HDFS is a distributed file system that is well suited for the storage of large files. Its documentation states that it is not, however, a general purpose file system, and does not provide fast individual record lookups in files. HBase, on the other hand, is built on top of HDFS and provides fast record lookups (and updates) for large tables. This can sometimes be a point of conceptual confusion. HBase internally puts your data in indexed StoreFiles that exist on HDFS for high-speed lookups.
Does HBase support SQL?
Not really. SQL-ish support for HBase via Hive is in development, however Hive is based on MapReduce which is not generally suitable for low-latency requests.
Are there any Schema Design examples?
Theres a very big difference between storage of relational/row-oriented databases and column-oriented databases. For example, if I have a table of users and I need to store friendships between these users... In a relational database my design is something like:
Table: users(pkey = userid) Table: friendships(userid,friendid,...) which contains one (or maybe two depending on how its impelemented) row for each friendship.
In order to lookup a given users friend, SELECT * FROM friendships WHERE userid = myid;
The cost of this relational query continues to increase as a user adds more friends. You also begin to have practical limits. If I have millions of users, each with many thousands of potential friends, the size of these indexes grow exponentially and things get nasty quickly. Rather than friendships, imagine Im storing activity logs of actions taken by users.
In a column-oriented database these things scale continuously with minimal difference between 10 users and 10,000,000 users, 10 friendships and 10,000 friendships.
Rather than a friendships table, you could just have a friendships column family in the users table. Each column in that family would contain the ID of a friend. The value could store anything else you would have stored in the friendships table in the relational model. As column families are stored together/sequentially on a per-row basis, reading a user with 1 friend versus a user with 10,000 friends is virtually the same. The biggest difference is just in the shipping of this information across the network which is unavoidable. In this system a user could have 10,000,000 friends. In a relational database the size of the friendship table would grow massively and the indexes would be out of control.
Can you please provide an example of good de-normalization in HBase and how its held consistent (in your friends example in a relational db, there would be a cascadingDelete)? As I think of the users table: if I delete an user with the userid=123, do I have to walk through all of the other users column-family friends to guaranty consistency?! Is de-normalization in HBase only used to avoid joins? Our webapp doesnt use joins at the moment anyway.
You lose any concept of foreign keys. You have a primary key, thats it. No secondary keys/indexes, no foreign keys.
Its the responsibility of your application to handle something like deleting a friend and cascading to the friendships. Again, typical small web apps are far simpler to write using SQL, you become responsible for some of the things that were once handled for you.
Another example of good denormalization would be something like storing a users favorite pages. If we want to query this data in two ways: for a given user, all of his favorites. Or, for a given favorite, all of the users who have it as a favorite. Relational database would probably have tables for users, favorites, and userfavorites. Each link would be stored in one row in the userfavorites table. We would have indexes on both userid and favoriteid and could thus query it in both ways described above. In HBase wed probably put a column in both the users table and the favorites table, there would be no link table.
That would be a very efficient query in both architectures, with relational performing better much better with small datasets but less so with a large dataset.
Now asking for the favorites of these 10 users. That starts to get tricky in HBase and will undoubtedly suffer worse from random reading. The flexibility of SQL allows us to just ask the database for the answer to that question. In a small dataset it will come up with a decent solution, and return the results to you in a matter of milliseconds. Now lets make that userfavorites table a few billion rows, and the number of users youre asking for a couple thousand. The query planner will come up with something but things will fall down and it will end up taking forever. The worst problem will be in the index bloat. Insertions to this link table will start to take a very long time. HBase will perform virtually the same as it did on the small table, if not better because of superior region distribution.
How would you design an Hbase table for many-to-many association between two entities, for example Student and Course?
I would define two tables:
Student: student id student data (name, address, ...) courses (use course ids as column qualifiers here) Course: course id course data (name, syllabus, ...) students (use student ids as column qualifiers here)
Does it make sense?
A[Jonathan Gray] : Your design does make sense.
As you said, youd probably have two column-families in each of the Student and Course tables. One for the data, another with a column per student or course. For example, a student row might look like: Student : id/row/key = 1001 data:name = Student Name data:address = 123 ABC St courses:2001 = (If you need more information about this association, for example, if they are on the waiting list) courses:2002 = ...
This schema gives you fast access to the queries, show all classes for a student (student table, courses family), or all students for a class (courses table, students family).
What is the maximum recommended cell size?
A rough rule of thumb, with little empirical validation, is to keep the data in HDFS and store pointers to the data in HBase if you expect the cell size to be consistently above 10 MB. If you do expect large cell values and you still plan to use HBase for the storage of cell contents, youll want to increase the block size and the maximum region size for the table to keep the index size reasonable and the split frequency acceptable.
Why cant I iterate through the rows of a table in reverse order?
Because of the way HFile works: for efficiency, column values are put on disk with the length of the value written first and then the bytes of the actual value written second. To navigate through these values in reverse order, these length values would need to be stored twice (at the end as well) or in a side file. A robust secondary index implementation is the likely solution here to ensure the primary use case remains fast.
Sqoop Import from MySql to Hbase
It is often a requirement to move your RDBMS(MySql) data to Hbase. Now we will have a look how we can import Mysql or any RDBMS table directly to Hadoop Hbase. we will use again “Sqoop Import” with hbase specific details. If you see in detail we have added
switches to instruct “sqoop import” command for importing data in hbase. “column family” is kind of prerequisite for Hbase table. So we have to provide a column family. “hbase-create-table” is explicitly stating sqoop to import data in hbase.
column-family and hbase-create-table twoswitches to instruct “sqoop import” command for importing data in hbase. “column family” is kind of prerequisite for Hbase table. So we have to provide a column family. “hbase-create-table” is explicitly stating sqoop to import data in hbase.
sqoop import --connect jdbc:mysql://localhost/test --username root --table tableName --hbase-table Name --column-family hbase_table_tutorial --hbase-create-table
I have attached a screen shot of commands line results. if you would remember Sqoop import has not get connected to zookeeper when we have imported data to hdfs.
Sqoop Import from MySql to Hive
This is another common requirement where we need to deal with MySql table import to Hive. We can still use sqoop import to perform the same task. we need to specify the
hive-table Destination table name.--create-hive-table --hive-import instructing sqoop that it will be a hive import operation for that commands need to create a table with specified table name.--hive- "location of hive directory"sqoop import -connect jdbc:mysql://localhost:3306/test -username root --table Name -- hive-table Name --create-hive-table --hive-import --hive-/user/hive/warehouseSqoop Import and Export MySql to HDFS
It’s one of the common use cases to import data in Hadoop or it subproject Hive/Hbase from one of RDBMS(Sql server, MySql, Oracle) to Hadoop. as Most of the organizations are using one way or other any type of RDBMS. To use Hadoop and churn out the available data we should have hands on commandsto accomplish these import /export to Hadoop.
I will demonstrate few use cases examples in this article to support in your live projects.
Sqoop import from MySql to HDFS
Sqoop provides feature to import MySql/Database data tables into HDFS directly through below mentioned command.
Sqoop provides feature to import MySql/Database data tables into HDFS directly through below mentioned command.
sqoop import -connect JDBC Drive/connection String -username DBUserName -Password --table TableName --target-dir Destination directorysqoop import -connect jdbc:mysql://localhost:3306/test -username root --table Name --target-dir DirName
In our case we don’t have a password set for Database so we can exclude -password switch.if we are using table import then it will import all the row with all columns. you can see below mentioned command in log, specifying sql query to import whole table.
INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `Name` AS t LIMIT 1
Now we are able to manage the data import from MySql to HDFS. It’s time to examine in hdfs file system.
[cloudera@localhost ~]$ hadoop fs -ls /user/cloudera/NameFound 3 items
-rw-r--r-- 3 cloudera cloudera 0 2014-09-29 00:07 /user/cloudera/Name/_SUCCESS
drwxr-xr-x - cloudera cloudera 0 2014-09-29 00:07 /user/cloudera/Name/_logs
-rw-r--r-- 3 cloudera cloudera 35 2014-09-29 00:07 /user/cloudera/Name/part-m-00000
Number of Maps Control
we can control the number of mappers to work on by specifying -m in the command itself.
we can control the number of mappers to work on by specifying -m in the command itself.
sqoop import -connect jdbc:mysql://localhost:3306/test -username root --table Name -m 1 --target-dir DirName
Condition Data import from sqoop
if we want to conditional import in sqoop, we may specify
if we want to conditional import in sqoop, we may specify
--where "Column > Value" with this specification only those rows would be imported, which will qualify the conditionsqoop import -connect jdbc:mysql://localhost:3306/test -username root --table Name -m 1 --target-dir DirName --where "tutorial_id"
Sqoop Also support to import result set from sql query. for that we need to specify
--query‘Query to produce result set’
All cases which we have discussed so far is assuming that you have a primary key in table. if we don’t have primary key, even we can import data from database to HDFS. for that we need to change our sqoop syntex a bit.
sqoop import -connect jdbc:mysql://localhost:3306/test -username root --table Name -m 1 --target-dir DirNameHBase Vs HDFS
We know that both Hbase and HDFS can stores data and provide flexible data model. Both of these HDFS is a distributed file system whereas on the other hand HBase is a distributed column oriented database. which works in top of HDFS. Both of these, have vital use in Hadoop technology. No doubt, Hadoop is the most suited in offline batch-processing whereas HBase is suitable when you have real-time requirements.
The tabular format of HBase is a database management system, which stores all of its data mainly in a distributed file system and its also a core part of Hadoop. HBase offers some of the beneficial features such as low latency access to lesser data amounts from within a large set of data. User can access the single rows swiftly from a million row table as well. Data models are flexible and easy to work with. It helps to provides minimal latency access to small sets of data from within a vast data set. Data is indexed efficiently by the row key. Fast scans possible across tables. Scale in terms of total amount of data as well as writes. Applications of HBase are written in Java similar to that of typical MapReduce application. HBase supports writing applications in Thrift, Avro and REST as well. It is best suited for storing large quantities of spare data sets that are much common in most of the big data use cases.
HDFS on the other hand, is kind of distributed file system having the vital properties such as; it is optimized for access of large files. One can typically store files, which are in the 100s of MB and over on HDFS and access them effortlessly through the tool Mapreduce to process in batch mode. HDFS files are a kind of write ones files. In some of recent version, it is possible to append to files, however this feature is not commonly utilized. HDFS files can be considered as read-many and write-once files. There is no model of random writes, even though HDFS does do random reads but not extremely well. HDFS has the capability to store vast amount of information that can be processed and accessed regardless of the operating system being used.
Hbase table creation and data manipulation from Java
6) Explain what is WAL and Hlog in Hbase?
WAL (Write Ahead Log) is similar to MySQL BIN log; it records all the changes occur in data. It is a standard sequence file by Hadoop and it stores HLogkey’s. These keys consist of a sequential number as well as actual data and are used to replay not yet persisted data after a server crash. So, in cash of server failure WAL work as a life-line and retrieves the lost data’s.
Explain why to use Hbase?
- High capacity storage system
- Distributed design to cater large tables
- Column-Oriented Stores
- Horizontally Scalable
- High performance & Availability
- Base goal of Hbase is millions of columns, thousands of versions and billions of rows
- Unlike HDFS (Hadoop Distribute File System), it supports random real time CRUD operations
Mention what are the key components of Hbase?
- Zookeeper: It does the co-ordination work between client and Hbase Maser
- Hbase Master: Hbase Master monitors the Region Server
- RegionServer: RegionServer monitors the Region
- Region: It contains in memory data store(MemStore) and Hfile.
- Catalog Tables: Catalog tables consist of ROOT and META.
Explain what does Hbase consists of?
- Hbase consists of a set of tables
- And each table contains rows and columns like traditional database
- Each table must contain an element defined as a Primary Key
- Hbase column denotes an attribute of an object
10) Explain deletion in Hbase? Mention what are the three types of tombstone markers in Hbase?
When you delete the cell in Hbase, the data is not actually deleted but a tombstone marker is set, making the deleted cells invisible. Hbase deleted are actually removed during compactions.
Three types of tombstone markers are there:
- Version delete marker: For deletion, it marks a single version of a column
- Column delete marker: For deletion, it marks all the versions of a column
- Family delete marker: For deletion, it marks of all column for a column family
1) Explain how does Hbase actually delete a row?
In Hbase, whatever you write will be stored from RAM to disk, these disk writes are immutable barring compaction. During deletion process in Hbase, major compaction process delete marker while minor compactions don’t. In normal deletes, it results in a delete tombstone marker- these delete data they represent are removed during compaction.
Also, if you delete data and add more data, but with an earlier timestamp than the tombstone timestamp, further Gets may be masked by the delete/tombstone marker and hence you will not receive the inserted value until after the major compaction.
12) Explain what happens if you alter the block size of a column family on an already occupied database?
When you alter the block size of the column family, the new data occupies the new block size while the old data remains within the old block size. During data compaction, old data will take the new block size. New files as they are flushed, have a new block size whereas existing data will continue to be read correctly. All data should be transformed to the new block size, after the next major compaction.